Zookeeper入门

Contents
一、Zookeeper 概述
1.1 zookeeper 是什么?
ZooKeeper 是 Apache 的顶级项目。ZooKeeper 为分布式应用提供了高效且可靠的分布式协调服务,提供了诸如统一命名服务、配置管理和分布式锁等分布式的基础服务。在解决分布式数据一致性方面,ZooKeeper 并没有直接采用 Paxos 算法,而是采用了名为 ZAB 的一致性协议。它的存在使开发者专注核心应用程序逻辑,而不必担心应用程序的分布式特性。
最初其作为研发Hadoop时的副产品。由于分布式系统中一致性处理较为困难,其他的分布式系统没有必要费劲重复造轮子,故随后的分布式系统中大量应用了zookeeper,以至于zookeeper成为了各种分布式系统的基础组件。著名的hadoop、kafka、dubbo 都是基于zookeeper 而构建。
1.2 应用场景
- 分布式协调组件 :冗余部署,数据一致性, watch 机制,
- 分布式锁:强一致性,顺序一致性,(ZAB协议)
- 无状态的实现:存放数据的中心
1.3 特性
- 顺序一致性: 所有客户端看到的服务端数据模型都是一致的;从一个客户端发起的事务请求,最终都会严格按照其发起顺序被应用到 ZooKeeper 中。具体的实现可见下文:原子广播。
- 原子性: 所有事务请求的处理结果在整个集群中所有机器上的应用情况是一致的,即整个集群要么都成功应用了某个事务,要么都没有应用。实现方式可见下文:事务。(一个更新操作成功,当且仅当大多数 Server 在内存中成功修改数据。)
- 单一视图: 无论客户端连接的是哪个 Zookeeper 服务器,其看到的服务端数据模型都是一致的。
- 高性能: ZooKeeper 将数据全量存储在内存中,所以其性能很高。需要注意的是:由于 ZooKeeper 的所有更新和删除都是基于事务的,因此 ZooKeeper 在读多写少的应用场景中有性能表现较好,如果写操作频繁,性能会大大下滑。
- 高可用: ZooKeeper 的高可用是基于副本机制实现的,此外 ZooKeeper 支持故障恢复,可见下文:选举 Leader。(Zookeeper 启动时,将从实例中选举一个 leader(Paxos 协议);)
二、核心概念
2.1 数据模型
ZooKeeper 的数据模型是一个树形结构的文件系统。
树中的节点被称为 znode,其中根节点为 /,每个节点上都会保存自己的数据和节点信息。znode 可以用于存储数据,并且有一个与之相关联的 ACL(详情可见 ACL)。ZooKeeper 的设计目标是实现协调服务,而不是真的作为一个文件存储,因此 znode 存储数据的大小被限制在 1MB 以内。
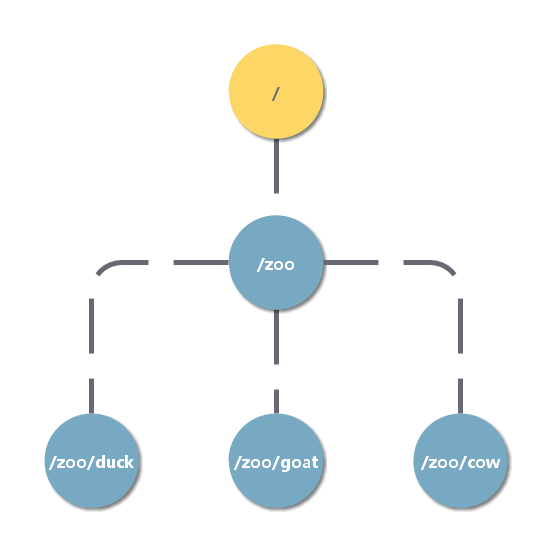
ZooKeeper 的数据访问具有原子性。 其读写操作都是要么全部成功,要么全部失败。
znode 通过路径被引用。znode 节点路径必须是绝对路径。 znode的数据结构包括下面四个部分:(get -s 命令可以查看属性)
- data:实际存储数据
- acl:权限数据操作权限
- stat:描述当前节点的元数据
- child:当前节点的子节点
znode 有6种类型:
-
临时节点( EPHEMERAL ): 客户端会话结束时,ZooKeeper 就会删除临时的 znode。
通过该特性,zk 可以实现服务注册和发现的效果。 -e
-
临时序号节点: 和持久序号节点相同,适用于临时的分布式锁。 (-s -e)
-
持久的(PERSISTENT ): 除非客户端主动执行删除操作,否则 ZooKeeper 不会删除持久的 znode。(默认性质)
-
持久序号节点: 创建出的节点,根据先后顺序,会在节点后带上一个数值,越后数值越大,适用于分布式锁的场景,单调递增。(-s)
-
Container 节点: Container 容器节点,当容器中没有任何子节点时,该容器节点会被 zk 定期删除(60 s) (-c)
-
TTL 节点: 可以指定节点的到期时间,到期后被 zk 定期删除。只能通过系统配置
zookeeper.extendedTypeEnable=true开启
2.2 节点信息(Stat: 元信息)
znode 上有一个顺序标志( SEQUENTIAL )。如果在创建 znode 时,设置了顺序标志( SEQUENTIAL ),那么 ZooKeeper 会使用计数器为 znode 添加一个单调递增的数值,即 zxid。ZooKeeper 正是利用 zxid 实现了严格的顺序访问控制能力。
每个 znode 节点在存储数据的同时,都会维护一个叫做 Stat 的数据结构,里面存储了关于该节点的全部状态信息。如下:(get -s nodename)
| 状态属性 | 说明 |
|---|---|
| czxid | 数据节点创建时的事务 ID |
| ctime | 数据节点创建时的时间 |
| mzxid | 数据节点最后一次更新时的事务 ID |
| mtime | 数据节点最后一次更新时的时间 |
| pzxid | 数据节点的子节点最后一次被修改时的事务 ID |
| cversion | 子节点的更改次数 |
| version | 节点数据的更改次数 |
| aversion | 节点的 ACL 的更改次数 |
| ephemeralOwner | 如果节点是临时节点,则表示创建该节点的会话的 SessionID;如果节点是持久节点,则该属性值为 0 |
| dataLength | 数据内容的长度 |
| numChildren | 数据节点当前的子节点个数 |
2.3 ACL 权限信息
ZooKeeper 采用 ACL(Access Control Lists)策略来进行权限控制。即规定什么样的用户能够操作这个节点,且进行操作权限。
- c : create 创建权限,允许该节点下创建子节点;
- w:write 更新权限,允许更新该节点的数据;
- r:read 读取权限,允许读取该节点的内容及其子节点的列表信息;
- d:delete 删除权限,允许删除该节点的子节点;
- a:admin 管理者权限,允许对该节点进行 acl 权限设置。
三、zookeeper 服务器搭建与Client 使用
3.1 zoo.cfg 文件说明

3.2 Zookeeper 服务器的操作命令
|
|
3.3 zkCli 客户端的使用
3.3.1 创建节点
|
|
3.3.1 查询节点
|
|
3.3.2 删除节点
|
|
3.3.3 修改节点信息
|
|
3.3.4 权限设置
|
|
在另一个会话中必须使用账号密码,才能拥有操作操作该节点权限
3.3.5 同步数据
|
|
Author 拾光
LastMod 2022-07-04