Collection初了解

Contents
前言:Collection 是最基本的集合接口,在 JDK 1.2 版本被引入到 Java 的世界中来。Collection 的出现,使得 Java 拥有了前所未有的强大能力。本文就将介绍 Collection 体系下常用的类的实现以及它们背后的数据结构。
Collection 体系简介
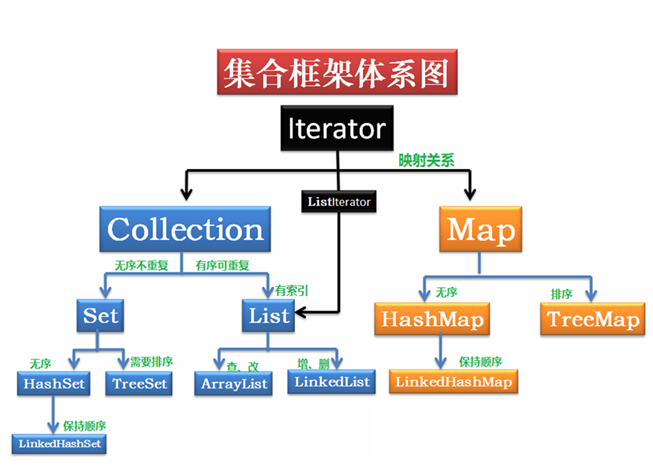
Java 集合框架(Java collections framework) 是一个包含一系列实作可重复使用集合的数据结构的类别 “类别 (计算机科学)")和界面"界面 (程式设计)")集合。 虽然称为“框架”,其使用方式却像个函式库。集合框架提供了定义各式各样集合的界面和实作上述集合的类别。
我们从 Idea 搜索 Collection.java.util 中可以看到其源代码,其第一段是如此说的:
The root interface in the collection hierarchy. A collection represents a group of objects, known as its elements. Some collections allow duplicate elements and others do not. Some are ordered and others unordered. The JDK does not provide any direct implementations of this interface: it provides implementations of more specific subinterfaces like Set and List. This interface is typically used to pass collections around and manipulate them where maximum generality is desired.
翻译过来就是:
Collection 是 Java Collection 继承体系中的根接口。一个 Collection 代表一组对象,被称为它的元素。有一些集合允许重复的元素(如List),而另一些则不允许重复(如 Set )。一些是有序的(如 ArrayList ),而有些则是无序的(如 HashSet )。 JDK 不提供对 Collection 这个接口的任何直接实现:它提供了很多对它子接口(如 Set 和 List )的实现。该接口通常用于在非常通用的地方把 Collection 当作参数传来传去,同时对它们进行操作。
Collection 体系下的三种结构
List(有序列表)
List 接口是一个有序的 Collection,使用此接口能够精确的控制每个元素插入的位置,能够通过索引(元素在List中位置,类似于数组的下标)来访问List中的元素,第一个元素的索引为 0,而且允许有相同的元素。List 接口存储一组不唯一,有序(插入顺序)的对象。
常用的List实现类有:ArrayList、LinkedList
Set(集合)
Set 具有与 Collection 完全一样的接口,只是行为上不同,Set 不保存重复的元素。Set 接口存储一组唯一,无序的对象。
常用的 Set 实现类有:HashSet
需要注意的是:Set 判断重复是通过 equals 方法。
Map(映射表)
Map 接口存储一组键值对象,提供 key(键)到 value(值)的映射。
常用的Map实现类:HashMap
Collection 体系常用实现类详解
一、List
ArrayList(线性结构,基于动态数组)
1.本质上,ArrayList 就是一个数组。
2.动态扩容的实现:创建一个更大空间的对象。然后把原先的所有元素拷贝过去。
线性结构
简单地说,线性结构就是表中各个结点具有线性关系。如果从数据结构的语言来描述,线性结构应该包括如下几点:
1、线性结构是非空集。
2、线性结构有且仅有一个开始结点和一个终端结点。
3、线性结构所有结点都最多只有一个直接前趋结点和一个直接后继结点。
线性表就是典型的线性结构,还有栈、队列和串等都属于线性结构。
LinkedList(链表)
链表
链表是一种数据元素按照链式存储结构进行存储的数据结构,这种存储结构具有在物理上存在非连续的特点。链表由一系列数据结点构成,每个数据结点包括数据域和指针域两部分。其中,指针域保存了数据结构中下一个元素存放的地址。链表结构中数据元素的逻辑顺序是通过链表中的指针链接次序来实现的。
ArrayList 和 LinkedList 比较
由于二者是基于不同的数据结构实现的,基于链表和线性结构的不同,二者主要的不同用法:
- ArrayList 对于【查】、【改】操作性能更高
- LinkedList 对与【增】、【删】操作性能更高,实现了
Deque双向链表和Queue单项链表
二、Set
HashSet 最常用,最高效的 Set 实现
- List 可以使用 Set 来去重
注意:HashSet是无序随机的,如果需要有序的 HashSet 可以使用 LinkedHashSet (按插入顺序排列)。 如果需要排好序的集合,可以使用 TreeSet。
散列表(Hash) 散列表源自于散列函数(Hash function),其思想是如果在结构中存在关键字和T相等的记录,那么必定在F(T)的存储位置可以找到该记录,这样就可以不用进行比较操作而直接取得所查记录。
TreeSet
TreeSet 是有序的,因为 Comparable 的默认顺序是从小到大,所以TreeSet的默认顺序是从小到大,即自然顺序。
因此:TreeSet 最大的用途就是用来排序的。TreeSet 内部的数据结构是红黑树。
树
树 是典型的非线性结构,它是包括,2个结点的有穷集合K。在树结构中,有且仅有一个根结点,该结点没有前驱结点。在树结构中的其他结点都有且仅有一个前驱结点,而且可以有两个后继结点,m≥0
LinkedHashSet(有顺序的HashSet)
保证内部顺序和插入的顺序一样。
三、Map
HashMap
HashMap 的线程不安全性
注意:HashMap 是线程不安全的,在 jdk 的官方注释中也提到了【Note that this implementation is not synchronized.】。即:请注意,HashMap 的实现没有被同步。
在多线程中,HashMap 的死循环问题:在多线程中,扩容的时候,即 resize 的时候,有可能变成一个死循环的链表。感兴趣的可以移步:疫苗:JAVA HASHMAP的死循环 。因此在多线程中,应该使用 ConcurrentHashMap,即并发的 HashMap。
解决办法:采用 ConcurrentHashMap(线程安全的 HashMap )
HashMap 在 jdk1.7 后的改变:同一个哈希桶中存储的数据结构由链表改为红黑树
如果恰好一个 Map 的所有的 key 的 hashCode 都是一样的,那么他们就会放到同一个哈希桶中,那么这个 HashMap 就会变成一个效率极低的链表,导致程序运行变慢,丧失了使用 Hash 算法的好处。JDK7 以后,发生哈希碰撞,存在同一个哈希桶中的数据不再是一个链表,而是变成了一个红黑树,从而提高了性能。
TreeMap
内部数据结构同 TreeSet,此处不再赘述。 HashMap 和 HashSet 本质上是⼀种东⻄
- HashMap 的 key 的 set 就是一个 HashSet
- HashSet 的实现中就包含了一个 HashMap
哈希算法简介
Java 世界里第二重要的约定(hashCode)
(第一重要的约定是 equals 约定)
-
同于一个对象必须始终返回相同的hashCode
-
两个对象的 equals 返回 true,则必须返回相同的 hashCode
- 因此,当我们重写 equals 方法时,必须重写 hashCode 方法
-
两个对象不等,也可能返回相同的 hashCode(原因参照上一条)
哈希就是一个单项的映射,举例来说就像百家姓:先把所有人按照姓来分类,然后再查找:人名怎么取 hashCode 呢,通过取他的姓;那对象 Object 就会通过hashCode 算法,映射成一个 int。
在内存中,上面百家姓的例子,姓就是内存中的哈希桶,通过 hashCode 方法算出一个哈希值,然后放到哈希桶中。如果我们有10万条数据,通过哈希算法分散到10万个哈希桶中,那么我们查找某一条数据,只需要查找一次,因此通过哈希算法,查找的时间复杂度是呈指数下降的。
四、Collection 的其他实现
Queue(队列)
有优先级的集合,LILO(Last In Last Out)
队列和栈类似,也是一种特殊的线性表。和栈不同的是,队列只允许在表的一端进行插入操作,而在另一端进行删除操作。一般来说,进行插入操作的一端称为队尾,进行删除操作的一端称为队头。队列中没有元素时,称为空队列。
Deque(双端队列)
允许在两端进行增删元素。
Veetor
Vector是 ArrayList 的前身,已弃用
Stack(栈)
LIFO(Last In First Out),如果需要”栈“这种数据结构,推荐使用Deque
栈 是一种特殊的线性表,它只能在一个表的一个固定端进行数据结点的插入和删除操作。栈按照后进先出的原则来存储数据,也就是说,先插入的数据将被压入栈底,最后插入的数据在栈顶,读出数据时,从栈顶开始逐个读出。栈在汇编语言程序中,经常用于重要数据的现场保护。栈中没有数据时,称为空栈。
PriorityQueue(使用”堆“来实现的优先级队列)
堆
堆是一种特殊的树形数据结构,一般讨论的堆都是二叉堆。堆的特点是根结点的值是所有结点中最小的或者最大的,并且根结点的两个子树也是一个堆结构
Author 拾光
LastMod 2021-05-21